Experiential Reinforcement Learning






Abstract
Reinforcement learning has become the central approach for language models (LMs) to learn from environmental reward or feedback. In practice, the environmental feedback is usually sparse and delayed. Learning from such signals is challenging, as LMs must implicitly infer how observed failures should translate into behavioral changes for future iterations.
We introduce Experiential Reinforcement Learning (ERL), a training paradigm that embeds an explicit experience–reflection–consolidation loop into the reinforcement learning process. Given a task, the model generates an initial attempt, receives environmental feedback, and produces a reflection that guides a refined second attempt, whose success is reinforced and internalized into the base policy.
This process converts feedback into structured behavioral revision, improving exploration and stabilizing optimization while preserving gains at deployment without additional inference cost. Across sparse-reward control environments and agentic reasoning benchmarks, ERL consistently improves learning efficiency and final performance over strong reinforcement learning baselines, achieving gains of up to +81% in complex multi-step environments and up to +11% in tool-using reasoning tasks.
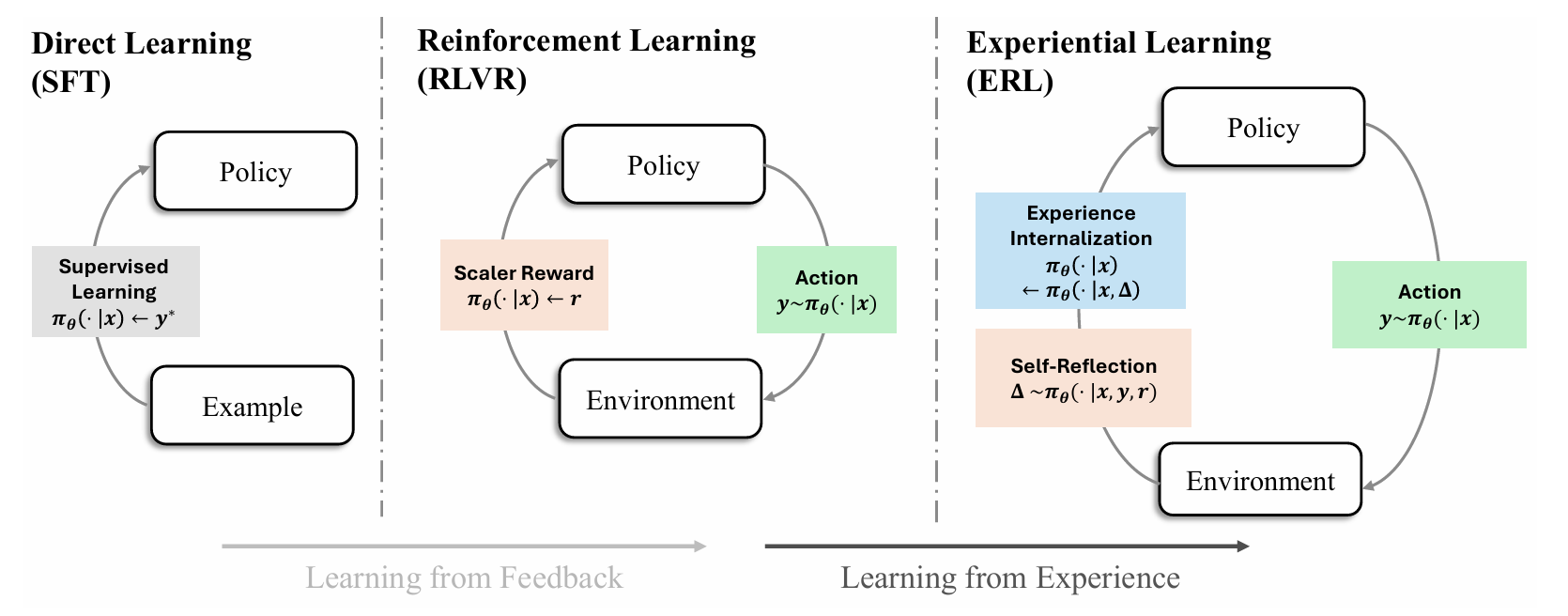
Overview
Experiential Reinforcement Learning (ERL) augments traditional reinforcement learning with an explicit loop:
- Experience — The model attempts a task and receives feedback
- Reflection — The model generates a structured critique
- Consolidation — The model attempts a second time and the successful revisions are internalized into the policy
This enables models to transform sparse rewards into actionable behavioral updates.
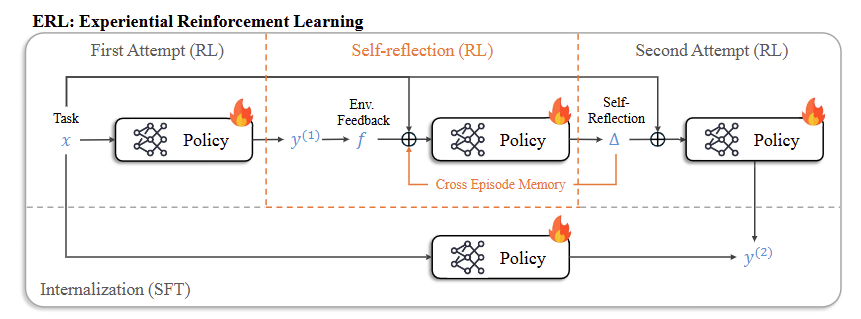
Motivation
Traditional RL with verifiable rewards (RLVR) relies on trial-and-error driven by scalar rewards, which can lead to inefficient exploration and unstable learning in sparse-reward environments.
ERL introduces structured intermediate reasoning to:
- Accelerate learning
- Enable within-episode correction
- Preserve improvements without reflection at inference
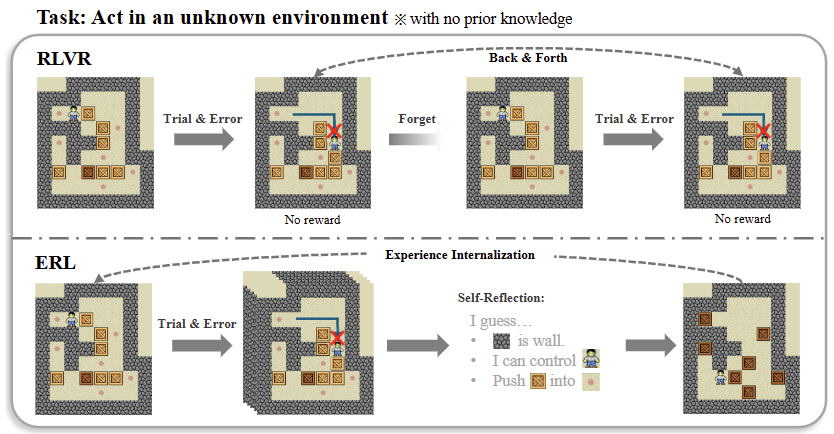
Method

Experiments
We evaluate ERL on:
- FrozenLake — Sparse-reward navigation
- Sokoban — Long-horizon planning
- HotpotQA — Tool-using reasoning
Models:
- Qwen3-4B-Instruct
- Olmo-3-7B-Instruct
Optimizer: GRPO
Results
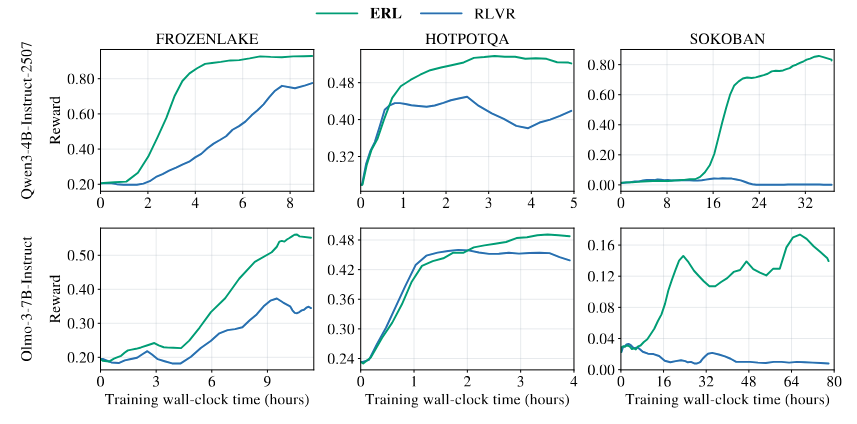
ERL consistently achieves:
- Faster convergence
- Higher final reward
- Improved learning efficiency
Final Performance
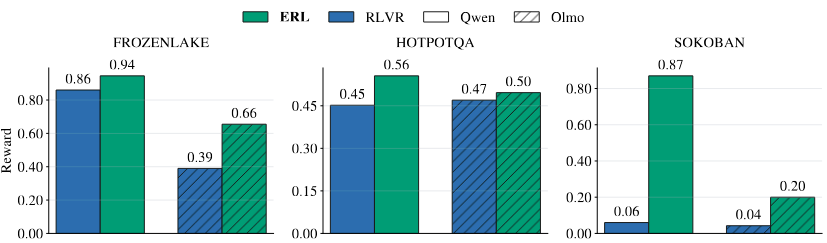
| Task | Qwen RLVR | Qwen ERL | Olmo RLVR | Olmo ERL |
|---|---|---|---|---|
| FrozenLake | 0.86 | 0.94 | 0.39 | 0.66 |
| HotpotQA | 0.45 | 0.56 | 0.47 | 0.50 |
| Sokoban | 0.06 | 0.87 | 0.04 | 0.20 |
Learning Dynamics
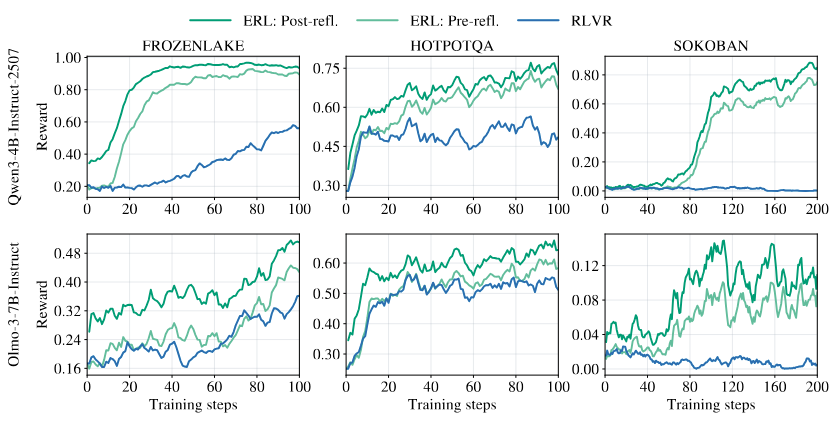
Post-reflection trajectories consistently outperform both pre-reflection and RLVR, demonstrating that reflection provides immediate within-episode improvement.
Ablation Study
| Task | RLVR | ERL | ERL w/o Memory | ERL w/o Reflection |
|---|---|---|---|---|
| FrozenLake (Qwen) | 0.86 | 0.94 | 0.86 | 0.60 |
| HotpotQA (Qwen) | 0.45 | 0.56 | 0.56 | 0.48 |
| Sokoban (Qwen) | 0.06 | 0.87 | 0.87 | 0.59 |
| FrozenLake (Olmo) | 0.39 | 0.66 | 0.64 | 0.54 |
| HotpotQA (Olmo) | 0.47 | 0.50 | 0.47 | 0.46 |
| Sokoban (Olmo) | 0.04 | 0.20 | 0.24 | 0.06 |
To isolate the contribution of individual components in ERL, we conduct ablations that remove either cross-episode memory or structured reflection while keeping the rest of the training setup fixed.
- ERL w/o Memory removes cross-episode reflection reuse but keeps within-episode reflection and retry.
- ERL w/o Reflection keeps the two-attempt structure but replaces structured reflection with a generic retry prompt.
Results show that removing reflection leads to the largest performance drop, indicating that structured reflective reasoning is the primary driver of ERL’s gains. Removing memory generally slows convergence and slightly reduces performance, suggesting it mainly improves stability and cumulative learning across episodes.
Key Contributions
- Introduces Experiential Reinforcement Learning, embedding reflection into RL training
- Proposes an internalization mechanism via selective distillation
- Demonstrates improved efficiency and performance across control and reasoning tasks
BibTeX
@misc{shi2026experientialreinforcementlearning,
title={Experiential Reinforcement Learning},
author={Taiwei Shi and Sihao Chen and Bowen Jiang and Linxin Song and Longqi Yang and Jieyu Zhao},
year={2026},
eprint={2602.13949},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2602.13949},
}